Ceph-PG
一、PG的产生
Ceph对集群中所有的存储资源进行池话管理(pool存储池)。针对一个存储池可以设计一组CRUSH规则。
Ceph将任意类型的前端数据都抽象成对象,每个对象采用算法生成一个全局唯一的标识(Object ID简称OID)。基于OID可以形成扁平的寻址空间。
为了实现不同pool之间的策略隔离,ceph不是讲对象数据直接映射存储在磁盘(OSD)上,而是引入一个中间结构,成为PG,实现两级映射。如下图所示。
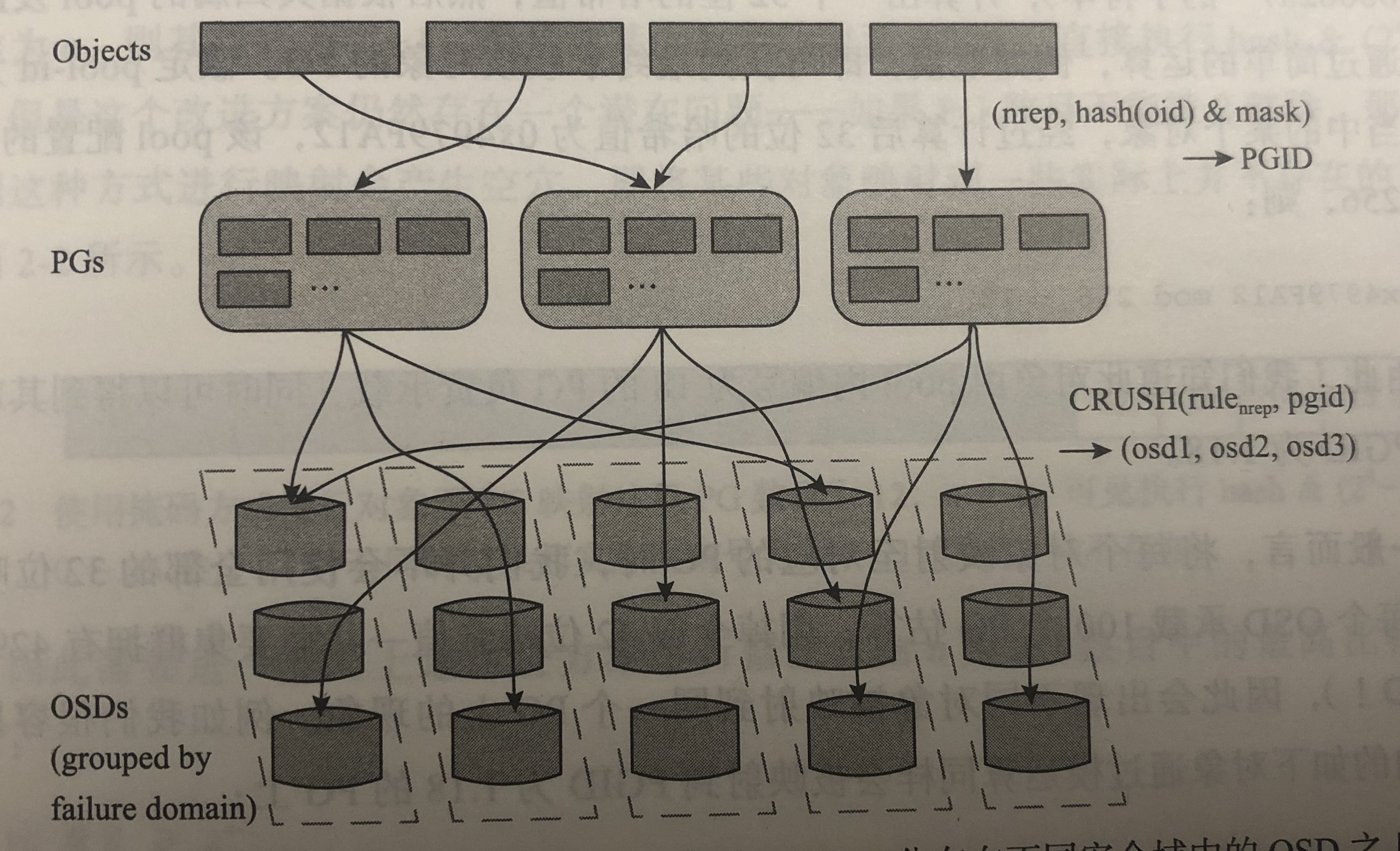
二、PG
二级映射第一级是静态的,负责将任何前端任何数据按照固定大小进行切割、编号后进行伪随机哈希计算,均匀映射到PG上,实现负载均衡策略。第二级映射实现PG到OSD的映射,这级映射依然采用伪哈希算法,但是除了全局唯一的PGID以外,还加入了集群拓补,并使用CRUSH规则对计算过程进行调整,帮助PG在不同OSD之间进行灵活迁移,实现数据可靠性和自动平衡等特性。
pool以PG作为基本单位进行组织,因此PG是一些对象的逻辑载体(集合)。
为了实现扁平寻址,要求PG也拥有一个全局唯一的标识(PGID)。因为所有的pool都由MON统一管理,所以MON给每个pool分配一个集群内的唯一标识(pool-id)。由此,我们只需要为pool内的PG分配一个pool内唯一标识就可以了。例如pool-id为1,那么这个pool内的PG就是1.0、1.1、1.2、…1.255这样的标识。
1.PG映射逻辑
PG映射方法称为stable_mod,其逻辑如下:
if ((hash & (2^n - 1)) < pg_num)
return (hash & (2^n - 1))
else
return (hash & (2^(n-1) - 1))
2^n - 1为PG的掩码
对于PG数能写成2^n形式的,直接将hash值与PG的掩码进行位与操作,得到的值在[0,2^n - 1],满足对象到pg的映射关系,映射pg编号为hash & (2^n - 1);
对于PG数不能写成2^n形式的,n取PG数目中的最高位比特(也就是向上取最近2^n),此时会多出不存在的PG([0,2^n - 1]),但是2^(n-1)的PG数是一定存在的,将多出来的PG重新映射到[0,2^(n-1)-1]这个区间。因此映射pg编号为hash & (2^(n-1) - 1);
因此在分配存储池时的PG数最好可以写成2^n形式,可以最大程度的让数据均匀分布。
2.PG分裂
ceph的设计理念之一是高可扩展行。在扩容前后如何让负载在所有OSD之间重新均衡是个问题,ceph通过PG自动迁移和重新平衡解决这一问题。然而,PG不会随着集群规模增长而自动增长,需要手动增加存储池的PG数目。PG数目的变化,会影响对象与PG的映射关系,从而需要同步转义这部分对象。这个过程叫做PG分裂,具体步骤如下:
1)Mon检测到pool中的PG数目发生修改时,发起并完成信息同步,随后将包含了变更信息的新OSDMap推送至相关OSD。
2)OSD接收到新OSDMap,与老OSDMap进行比对,判断对应的PG是否需要进行分裂。如果新老OSDMap中某个pool的PG数不一致,则需要执行分裂。(目前PG数只能增加)
3)假定这个pool的PG数为2^4,新的PG数为2^6,以pool中某个PGID=Y.X(X=0b X1X2X3X4)其哈希值特征如下:
| 0 | 0 | X1 | X2 | X3 | X4 |
|---|---|---|---|---|---|
| 0 | 1 | X1 | X2 | X3 | X4 |
| 1 | 0 | X1 | X2 | X3 | X4 |
| 1 | 1 | X1 | X2 | X3 | X4 |
PG分裂前后哈希值只有后6位有效,因此只列出后6位。之后依次对其进行新的PG数的stable_mod计算:
| 对象哈希值 | stable_mod计算结果 |
|---|---|
| 0b???? ???? ???? ???? ???? ???? ??00 X1X2X3X4 | X |
| 0b???? ???? ???? ???? ???? ???? ??01 X1X2X3X4 | 1*16+X |
| 0b???? ???? ???? ???? ???? ???? ??10 X1X2X3X4 | 2*16+X |
| 0b???? ???? ???? ???? ???? ???? ??11 X1X2X3X4 | 3*16+X |
可见,重新进行stable_mod计算后,只有第一种类型的对象能够映射到老PG上,其他三个对象皆没有实际PG对应,因此需要创建3个新的PG,三个新的PG的编号为(m*16 + X) m=1,2,3。
对所有老PG重复上述过程,最终可以将PG扩充为原来的4倍。又因为新的PG总是基于老的PG(称为祖先PG)产生,并且新的PG中最初的对象全部来自于老的PG,所以这个过程被称为PG分裂。
3.PGP
引入PG分裂之后,如果仍然直接使用PGID作为CRUSH输入,据此计算新增孩子PG在OSD之间的映射结果,由于此时每个PG的PGID都不相同,那么将引发大量新增孩子PG在OSD之间迁移。考虑到分裂之前PG在集群OSD之间的分布已经趋于均衡,更好的方法是让同一个祖先的孩子PG何其保持相同的分布,这样分裂之后整个集群的PG分布依然是均衡的。为此,每个存储池除了记录当前的PG数之外,为了应对PG分裂,还需要记录分裂之前祖先PG的个数,后者称为PGP数目(pgp_num)。
最后,利用CRUSH将每个PG分布到不同安全域中的OSD上是,我们不是直接使用PGID,而是使用其在存储池内的唯一编号针对PGP数目执行stable_mod计算,再和pool-id一起,哈希之后作为CRUSH的特征输入,从而保证每个孩子PG和其祖先取得相同的CRUSH计算结果(因为此时同一个祖先孩子PG产生的x都相同)。
因此,在初始创建存储池时,PG和PGP的数量保持一致。第一次扩充时,只需要增加PG数量;第二次及以后扩充时,需要将PGP改为扩充前的PG值。
4.PG数计算
参考:https://ceph.com/pgcalc/
参考资料:
《Ceph设计原理与实现》